- Research
- Open access
- Published:
Inequalities involving Dresher variance mean
Journal of Inequalities and Applications volume 2013, Article number: 366 (2013)
Abstract
Let p be a real density function defined on a compact subset Ω of , and let be the expectation of f with respect to the density function p. In this paper, we define a one-parameter extension of the usual variance of a positive continuous function f defined on Ω. By means of this extension, a two-parameter mean , called the Dresher variance mean, is then defined. Their properties are then discussed. In particular, we establish a Dresher variance mean inequality , that is to say, the Dresher variance mean is a true mean of f. We also establish a Dresher-type inequality under appropriate conditions on r, s, , ; and finally, a V-E inequality that shows that can be compared with . We are also able to illustrate the uses of these results in space science.
MSC:26D15, 26E60, 62J10.
1 Introduction and main results
As indicated in the monograph [1], the concept of mean is basic in the theory of inequalities and its applications. Indeed, there are many inequalities involving different types of mean in [1–18], and a great number of them have been used in mathematics and other natural sciences.
Dresher in [14], by means of moment space techniques, proved the following inequality: If , , and ϕ is a distribution function, then
This result is referred to as Dresher’s inequality by Daskin [15], Beckenbach and Bellman [16] (§24 in Ch. 1) and Hu [18] (p.21). Note that if we define
and
then the above inequality can be rewritten as
is the well-known Dresher mean of the function f (see [10, 11, 14–18]), which involves two parameters r and s and has applications in the theory of probability.
However, variance is also a crucial quantity in probability and statistics theory. It is, therefore, of interest to establish inequalities for various variances as well. In this paper, we introduce generalized ‘variances’ and establish several inequalities involving them. Although we may start out under a more general setting, for the sake of simplicity, we choose to consider the variance of a continuous function f with respect to a weight function p (including probability densities) defined on a closed and bounded domain Ω in instead of a distribution function.
More precisely, unless stated otherwise, in all later discussions, let Ω be a fixed, nonempty, closed and bounded domain in and let be a fixed function which satisfies . For any continuous function , we write
which may be regarded as the weighted mean of the function f with respect to the weight function p.
Recall that the standard variance (see [12] and [19]) of a random variable f with respect to a density function p is
We may, however, generalize this to the γ-variance of the function defined by
According to this definition, we know that γ-variance is a functional of the function and , and such a definition is compatible with the generalized integral means studied elsewhere (see, e.g., [1–6]). Indeed, according to the power mean inequality (see, e.g., [1–9]), we may see that
Let and be two continuous functions. We define
is the γ-covariance of the function and the function , where and the function is defined as follows:
According to this definition, we get
and
If we define
is the γ-absolute covariance of the function and the function , then we have that
for by the Cauchy inequality
Therefore, we can define the γ-correlation coefficient of the function and the function as follows:
where .
By means of , we may then define another two-parameter mean. This new two-parameter mean will be called the Dresher variance mean of the function f. It is motivated by (1) and [10, 11, 14–18] and is defined as follows. Given and the continuous function . If f is a constant function defined by for any , we define the functional
and if f is not a constant function, we define the functional
Since the function is continuous, we know that the functions and are integrable for any . Thus and are well defined. Since
is continuous with respect to and continuous with respect to .
We will explain why we are concerned with our one-parameter variance and the two-parameter mean by illustrating their uses in statistics and space science.
Before doing so, we first state three main theorems of our investigations.
Theorem 1 (Dresher variance mean inequality)
For any continuous function , we have
Theorem 2 (Dresher-type inequality)
Let the function be continuous. If , , and , then
Theorem 3 (V-E inequality)
For any continuous function , we have
moreover, the coefficient in (4) is the best constant.
From Theorem 1, we know that is a certain mean value of f. Theorem 2 is similar to the well-known Dresher inequality stated in Lemma 3 below (see, e.g., [2], p.74 and [10, 11]). By Theorem 2, we see that and can be compared under appropriate conditions on r, s, , . Theorem 3 states a connection of with the weighted mean .
Let Ω be a fixed, nonempty, closed and bounded domain in , and let be the density function with support in Ω for the random vector . For any function , the mean of the random variable is
moreover, its variance is
Therefore,
may be regarded as a γ-variance and
may be regarded as a Dresher variance mean of the random variable .
Note that by Theorem 1, we have
and by Theorem 2, we see that for any r, s, , such that
then
and by Theorem 3, if , then
where the coefficient is the best constant.
In the above results, Ω is a closed and bounded domain of . However, we remark that our results still hold if Ω is an unbounded domain of or some values of f are 0, as long as the integrals in Theorems 1-3 are convergent. Such extended results can be obtained by standard techniques in real analysis by applying continuity arguments and Lebesgue’s dominated convergence theorem, and hence we need not spell out all the details in this paper.
2 Proof of Theorem 1
For the sake of simplicity, we employ the following notations. Let n be an integer greater than or equal to 2, and let . For real n-vectors and , the dot product of p and x is denoted by , where and , is an -dimensional simplex. If ϕ is a real function of a real variable, for the sake of convenience, we set the vector function
Suppose that and . If , then
is called the γ-variance of the vector x with respect to p. If is a constant n-vector, then we define
while if x is not a constant vector (i.e., there exist such that ), then we define
is called the Dresher variance mean of the vector x.
Clearly, is nonnegative and is continuous with respect to . and is also continuous with respect to in .
Lemma 1 Let I be a real interval. Suppose the function is , i.e., twice continuously differentiable. If and , then
where Φ is the triangle and
Proof Note that
Hence,
Therefore, (8) holds. The proof is complete. □
Remark 1 The well-known Jensen inequality can be described as follows [20–22]: If the function satisfies for all t in the interval I, then for any and , we have
The above proof may be regarded as a constructive proof of (9).
Remark 2 We remark that the Dresher variance mean extends the variance mean (see [2], p.664, and [13, 21]), and Lemma 1 is a generalization of (2.23) of [19].
Lemma 2 If , and , then
Proof If x is a constant vector, our assertion is clearly true. Let x be a non-constant vector, that is, there exist such that . Note that and is continuous with respect to in , we may then assume that
In (8), let be defined by , where . Then we obtain
Since
by (11), (12), and the fact that
we obtain (10). This concludes the proof. □
We may now turn to the proof of Theorem 1.
Proof First, we may assume that f is a nonconstant function and that
Let
be a partition of Ω, and let
be the ‘norm’ of the partition T, where
is the length of the vector . Pick any for each , set
and
then
where is the m-dimensional volume of for .
Furthermore, when , we have
By (14), we obtain
By Lemma 2, we have
From (15) and (16), we obtain
This completes the proof of Theorem 1. □
Remark 3 By [21], if the function has the property that is a continuous and convex function, then for any and , we obtain
Thus, according to the proof of Theorem 1, we may see that: If the function is continuous and the function has the property that is a continuous convex function, then
where is the composite of ϕ and f. Therefore, the Dresher variance mean has a wide mathematical background.
3 Proof of Theorem 2
In this section, we use the same notations as in the previous section. In addition, for fixed , if and , then the γ-order power mean of x with respect to p (see, e.g., [1–9]) is defined by
and the two-parameter Dresher mean of x (see [10, 11]) with respect to p is defined by
We have the following well-known power mean inequality [1–9]: If , then
We also have the following result (see [2], p.74, and [10, 11]).
Lemma 3 (Dresher inequality)
If , and , then the inequality
holds if and only if
Proof Indeed, if (20) hold, since , we may assume that and . By the power mean inequality, we have
If (19) holds, by [2], p.74 and [10, 11], (20) hold. □
Lemma 4 Let , and . If (20) holds, then
Proof If x is a constant n-vector, our assertion clearly holds. We may, therefore, assume that there exist such that . We may further assume that
Let be a partition of . Let the area of each be denoted by , and let
be the ‘norm’ of the partition, then for any , we have
By (11), when , we have
By (21) and Lemma 3, we then see that
This ends the proof. □
We may now easily obtain the proof of Theorem 2.
Proof Indeed, by (20), (15) and Lemma 4, we get that
This completes the proof of Theorem 2. □
4 Proof of Theorem 3
In this section, we use the same notations as in the previous two sections. In addition, let be an n-vector and
let be the -dimensional simplex that
and let
be defined on .
Lemma 5 Let . If x is a relative extremum point of the function , then there exist and such that
and
Proof Consider the Lagrange function
with
where the function is defined by
Then
Note that
Hence, the function has at most one extreme point, and has at most two roots in . By (24), we have
where denotes the count of elements in the set . Since is a symmetric function, we may assume that there exists such that
That is, (23) and (22) hold. The proof is complete. □
Lemma 6 Let . If x is a relative extremum point of the function , then
Proof By Lemma 5, there exist and such that (23) and (22) hold. If , then (25) holds. We may, therefore, assume without loss of generality that . From (22), we see that
Putting (26) into (23), we obtain that
where the auxiliary function is defined by
Since , by (27), inequality (25) is equivalent to the following inequality:
By the software Mathematica, we can depict the image of the function in Figure 1, and the image of the function in Figure 2.

The graph of the function .

The graph of the function .
Now, let us prove the following inequalities:
By Cauchy’s mean value theorem, there exists such that
Therefore, inequality (29) holds.
Next, note that
By Lagrange’s mean value theorem, there exists such that
Hence, (31) holds. It then follows that inequality (30) holds.
By inequalities (29) and (30), we may easily obtain inequality (28). This ends the proof of Lemma 6. □
Lemma 7 If , then for any , inequality (25) holds.
Proof We proceed by induction.
-
(A)
Suppose . By the well-known non-linear programming (maximum) principle and Lemma 6, we only need to prove that
We show the first inequality, the second being similar.
Indeed, it follows from Lagrange’s mean value theorem that there exists such that
-
(B)
Assume by induction that the function satisfies for all . We prove inequality (25) as follows. By Lemma 6, we only need to prove that
We will only show the last inequality. If we set
then . By Lagrange’s mean value theorem, there exists such that
Thus, by the power mean inequality
and induction hypothesis, we see that
This ends the proof of Lemma 7. □
Lemma 8 Let and . If , then
and the coefficient in (32) is the best constant.
Proof We may assume that there exist such that . By continuity considerations, we may also assume that .
-
(A)
Suppose . Then (32) can be rewritten as
or
or
That is,
where we have introduced the auxiliary function
Since, for any , we have , we may assume that . By Lemma 7, we have
Hence, for a fixed , is increasing with respect to γ in . Thus, by , we obtain (33) and (32).
-
(B)
Suppose , but . Then there exists such that for . Setting
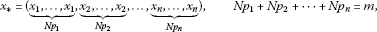
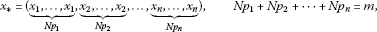
and
then , . Inequality (32) can then be rewritten as
According to the result in (A), inequality (34) holds.
-
(C)
Suppose and . Then it is easy to see that there exists a sequence such that . According to the result in (B), we get
Therefore
Next, we show that the coefficient is the best constant in (32). Assume that the inequality
holds. Setting

and in (35), we obtain
In (36), by letting , we obtain
Hence, the coefficient is the best constant in (32). The proof is complete. □
Remark 4 If , and , then there cannot be any and such that
Indeed, if there exist and such that (37) holds, then by setting

and in (37), we see that
which implies
which is a contradiction.
Remark 5 The method of the proof of Lemma 8 is referred to as the descending method in [6, 7, 13, 23–27], but the details in this paper are different.
We now return to the proof of Theorem 3.
Proof By (15) and Lemma 8, we obtain
Thus, inequality (4) holds. Furthermore, by Lemma 8, the coefficient is the best constant. This completes the proof of Theorem 3. □
5 Applications in space science
It is well known that there are nine planets in the solar system, i.e., Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune and Pluto. In this paper, we also believe that Pluto is a planet in the solar system. In space science, we always consider the gravity to the Earth from other planets in the solar system (see Figure 3).

The graph of the planet system .
We can build the mathematical model of the problem. Let the masses of these planets be , where denotes the mass of the Earth and . At moment , in , let the coordinate of the center of the Earth be and the center of the i th planet be , and the distance between and o be , where . By the famous law of gravitation, the gravity to the Earth o from the planets is
where is the gravitational constant in the solar system. Assume the coordinate of the center of the sun is , then there exists a ball such that the planets move in this ball. In other words, at any moment, we have
where r is the radius of the ball .
We denote by the angle between the vectors and , where . This angle is also considered as the observation angle between two planets , from the Earth o, which can be measured from the Earth by telescope.
Without loss of generality, we suppose that , , and in this paper.
We can generalize the above problem to an Euclidean space. Let  be an Euclidean space. For two vectors and , the inner product of α, β and the norm of α are denoted by and , respectively. The angle between α and β is denoted by
be an Euclidean space. For two vectors and , the inner product of α, β and the norm of α are denoted by and , respectively. The angle between α and β is denoted by
where α and β are nonzero vectors.
Let , we say the set
is a closed sphere and the set
is a spherical, where .
Now let us define the planet system and the λ-gravity function.
Let  be an Euclidean space, the dimension of , and be the sequences of and , respectively, and be a closed sphere in . The set
be an Euclidean space, the dimension of , and be the sequences of and , respectively, and be a closed sphere in . The set
is called the planet system if the following three conditions hold:
(H1) , ;
(H2) , ;
(H3) .
Let be a planet system. The function
is called a λ-gravity function of the planet system , and is the gravity kernel of , where .
Write
The matrix is called an observation matrix of the planet system , (, , ) and () are called the observation angle and the center observation angle of the planet system, respectively. For the planet system, we always consider that the observation matrix A is a constant matrix in this paper.
It is worth noting that the norm of the gravity kernel is independent of ; furthermore,
where is the transpose of the row vector m, and
is a quadratic.
In fact, from and , we have that
Let be a planet system. By the above definitions, the gravity to the Earth o from n planets in the solar system is , and is the norm of . If we take a point in the ray such that , and place a planet at with mass for , then the gravity of these n planets to the Earth o is .
Let be a planet system. If we believe that g is a molecule and are atoms of g, then the gravity to another atom o from n atoms of g is .
In the solar system, the gravity of n planets to the planet o is , while for other galaxy in the universe, the gravity may be , where .
Let be a planet system. Then the function
is called an absolute λ-gravity function of the planet system , where .
Let P be a planetary sequence in the solar system. Then is the average value of the gravities of the planets to the Earth o.
Let P be a planetary sequence in the solar system. If we think that is the radiation energy of the planet , then, according to optical laws, the radiant energy received by the Earth o is , , and the total radiation energy received by the Earth o is , where is a constant.
By Minkowski’s inequality (see [28])
we know that if and are a λ-gravity function and an absolute λ-gravity function of the planet system , respectively, then we have
Now, we will define absolute λ-gravity variance and λ-gravity variance. To this end, we need the following preliminaries.
Two vectors x and y in are said to be in the same (opposite) direction if (i) or , or (ii) and and x is a positive (respectively negative) constant multiple of y. Two vectors x and y in the same (opposite) direction are indicated by (respectively ).
We say that the set is a unit sphere in .
For each , we say that the set
is the tangent plane to the unit sphere  at the vector α. It is obvious that
at the vector α. It is obvious that
Assume that , and that . We then say that the set
where
are straight lines on the unit sphere , and that the sets
are the straight line segments on the sphere , and that is the length of these line segments.
It is easy to see that implies . Thus, we may easily get the existence and uniqueness of these line segments. Similarly, implies that .
Assuming that , and that α, β, γ are linearly dependent vectors, we say that is the tangent vector to the line segment at α. By definition, we see that there exist such that
Therefore
We infer from that
We define also the tangent vector of at α by . The tangent vector enjoys the following properties: If , then
In fact, there exists such that
Since , we see that
The angle between two line segments , on the unit sphere is defined as
If , , are three straight line segments on the unit sphere , and , then we say that the set is a spherical triangle. Write , , , , , . Then we obtain that
Thus, we may get the law of cosine for spherical triangle
By (42) we may get the law of cosine for spherical triangle
By (42) we may get the law of sine for spherical triangle
By , and (42)-(43), we get
or
and
Lemma 9 Let be an Euclidean space, let the dimension of satisfy , and let be a closed sphere in . If , then
Proof From we get
Thus,
Similarly, from we have
If we set
then . According to inequalities (48), (49) and (45), we get
hence
Now we discuss the conditions such that the equality in inequality (50) holds. From the above analysis, we know that these conditions are:
-
(a)
and ;
-
(b)
and ;
-
(c)
and .
From (a) and (b) we know that the condition (c) can be rewritten as
(c∗) or .
Based on the above analysis, we know that the equality in inequality (50) can hold. Therefore, equality (47) holds. The lemma is proved. □
It is worth noting that if is a planet system and , according to Lemma 9 and , then we have that
for any , and
where
Now, we will define absolute λ-gravity variance and λ-gravity variance.
Let be a planet system, and let the functions , be an absolute λ-gravity function and a λ-gravity function of the planet system, respectively. We say the functions
and
are absolute λ-gravity variance and λ-gravity variance of the planet system, respectively, where
Let be a planet system, and , , . By Lemma 2, we have
If , according to (51)-(54) and Lemma 2, we have
Let P be a planetary sequence in the solar system, and the gravity of the planet to the Earth o is , . Then inequalities (55) and (56) can be rewritten as
and
respectively.
Let be a planet system. By Lemma 8, if , then
If and , according to (51)-(54) and Lemma 8, we have
where the coefficient is the best constant in (59) and (60).
Remark 6 For some new literature related to space science, please see [4] and [25].
References
Bullen PS, Mitrinnović DS, Vasić PM: Means and Their Inequalities. Reidel, Dordrecht; 1988.
Kuang JC: Applied Inequalities. Shandong Sci. & Tech. Press, Jinan; 2004. (in Chinese)
Mitrinović DS, Pečarić JE, Fink AM: Classic and New Inequalities in Analysis. Kluwer Academic, Dordrecht; 1993.
Wen JJ, Gao CB: Geometric inequalities involving the central distance of the centered 2-surround system. Acta Math. Sin. 2008, 51(4):815–832. (in Chinese)
Wang WL, Wen JJ, Shi HN: On the optimal values for inequalities involving power means. Acta Math. Sin. 2004, 47(6):1053–1062. (in Chinese)
Wen JJ, Wang WL: The optimization for the inequalities of power means. J. Inequal. Appl. 2006., 2006: Article ID 46782 10.1155/JIA/2006/46782
Pečarić JE, Wen JJ, Wang WL, Lu T: A generalization of Maclaurin’s inequalities and its applications. Math. Inequal. Appl. 2005, 8(4):583–598.
Wen JJ, Cheng SS, Gao CB: Optimal sublinear inequalities involving geometric and power means. Math. Bohem. 2009, 134(2):133–149.
Ku HT, Ku MC, Zhang XM: Generalized power means and interpolating inequalities. Proc. Am. Math. Soc. 1999, 127(1):145–154. 10.1090/S0002-9939-99-04845-5
Páles Z: Inequalities for sums of powers. J. Math. Anal. Appl. 1988, 131(1):265–270. 10.1016/0022-247X(88)90204-1
Bjelica M: Asymptotic planarity of Dresher mean values. Mat. Vesn. 2005, 57: 61–63.
Wen JJ, Han TY, Gao CB: Convergence tests on constant Dirichlet series. Comput. Math. Appl. 2011, 62(9):3472–3489. 10.1016/j.camwa.2011.08.064
Yang H, Wen JJ, Wang WL: The method of descending dimension for establishing inequalities (II). Sichuan Daxue Xuebao 2007, 44(4):753–758.
Dresher M: Moment spaces and inequalities. Duke Math. J. 1953, 20: 261–271. 10.1215/S0012-7094-53-02026-2
Daskin JM: Dresher’s inequality. Am. Math. Mon. 1952, 49: 687–688.
Beckenbach EF, Bellman R: Inequalities. 3rd edition. Springer, Berlin; 1971.
Brenner JL, Carlson BC: Homogenous mean values: weights and asymptotes. J. Math. Anal. Appl. 1987, 123: 265–280. 10.1016/0022-247X(87)90308-8
Hu K: Problems in Analytic Inequality. Wuhan University Press, Wuhan; 2003. (in Chinese)
Wen JJ, Zhang ZH: Jensen type inequalities involving homogeneous polynomials. J. Inequal. Appl. 2010., 2010: Article ID 850215
Pečarić JE, Svrtan D: New refinements of the Jensen inequalities based on samples with repetitions. J. Math. Anal. Appl. 1998, 222: 365–373. 10.1006/jmaa.1997.5839
Wen JJ: The inequalities involving Jensen functions. J. Syst. Sci. Math. Sci. 2007, 27(2):208–218. (in Chinese)
Gao CB, Wen JJ: Inequalities of Jensen-Pečarić-Svrtan-Fan type. J. Inequal. Pure Appl. Math. 2008., 9: Article ID 74
Timofte V: On the positivity of symmetric polynomial functions. J. Math. Anal. Appl. 2003, 284: 174–190. 10.1016/S0022-247X(03)00301-9
Wen JJ, Yuan J, Yuan SF: An optimal version of an inequality involving the third symmetric means. Proc. Indian Acad. Sci. Math. Sci. 2008, 118(4):505–516. 10.1007/s12044-008-0038-0
Gao CB, Wen JJ: Theory of surround system and associated inequalities. Comput. Math. Appl. 2012, 63: 1621–1640. 10.1016/j.camwa.2012.03.037
Wen JJ, Wang WL: Chebyshev type inequalities involving permanents and their application. Linear Algebra Appl. 2007, 422(1):295–303. 10.1016/j.laa.2006.10.014
Wen JJ, Wang WL: The inequalities involving generalized interpolation polynomial. Comput. Math. Appl. 2008, 56(4):1045–1058. 10.1016/j.camwa.2008.01.032
Gardner RJ: The Brunn-Minkowski inequality. Bull., New Ser., Am. Math. Soc. 2002, 39: 355–405. 10.1090/S0273-0979-02-00941-2
Acknowledgements
This work is supported by the Natural Science Foundation of China (No. 10671136) and the Natural Science Foundation of Sichuan Province Education Department (No. 07ZA207).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
All authors contributed equally and significantly in this paper. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Wen, J., Han, T. & Cheng, S.S. Inequalities involving Dresher variance mean. J Inequal Appl 2013, 366 (2013). https://doi.org/10.1186/1029-242X-2013-366
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1029-242X-2013-366