- Research Article
- Open access
- Published:
From Equivalent Linear Equations to Gauss-Markov Theorem
Journal of Inequalities and Applications volume 2010, Article number: 259672 (2010)
Abstract
Gauss-Markov theorem reduces linear unbiased estimation to the Least Squares Solution of inconsistent linear equations while the normal equations reduce the second one to the usual solution of consistent linear equations. It is rather surprising that the second algebraic result is usually derived in a differential way. To avoid this dissonance, we state and use an auxiliary result on equivalence of two systems of linear equations. This places us in a convenient position to attack on the main problems in the Gauss-Markov model in an easy way.
1. Introduction
The Gauss-Markov theorem is the most classical achievement in statistics. Its role in statistics is comparable with that of the Pythagorean theorem in geometry. In fact, there are close relations between both of them.
The Gauss-Markov theorem is presented in many books and derived in many ways. The most popular approaches involve
(i)geometry (cf., Kruskal [1, 2]),
(ii)differential calculus (cf., Scheffé [3], Rao [4]),
(iii)generalized inverse matrices (cf., Rao and Mitra [5], Bapat [6]),
(iv)projection operators (see Seber [7]).
We presume that such a big market has many clients. This paper is intended for some of them. Our consideration is straightforward and self-contained. Moreover, it needs only moderate prerequisites.
The main tool used in this paper is equivalence of two systems of linear equations.
2. Preliminaries
For any matrix  of
of  define the sets
define the sets

We note that

It is clear that the range  constitutes
constitutes  -dimensional linear space in
-dimensional linear space in  spanned by the columns of
spanned by the columns of  , where
, where  , while
, while  constitutes
constitutes  -dimensional space of all vectors being orthogonal to any vector in
-dimensional space of all vectors being orthogonal to any vector in  relative to the usual inner product
relative to the usual inner product  Thus, any vector
Thus, any vector  may be presented in the form
may be presented in the form

Since  if and only if
if and only if  and, hence,
and, hence,  , we get
, we get 
Denote by  the linear operator from
the linear operator from  onto
onto  defined by
defined by

(i.e., the orthogonal projector onto  )
) It follows from definition (2.4) that
It follows from definition (2.4) that  The following lemma (see [8]) will be a key tool in the further consideration.
The following lemma (see [8]) will be a key tool in the further consideration.
Lemma 2.1.
For any matrix  and for any vector
and for any vector  , the following are equivalent:
, the following are equivalent:
(i)
(ii)
Proof.
(i) (ii) is evident (without any condition on
(ii) is evident (without any condition on  ).
).
(ii) (i). By the assumption that
(i). By the assumption that  , we get
, we get  for some
for some  . Thus, (ii) reduces to
. Thus, (ii) reduces to  and its general solution is
and its general solution is  , where
, where  . Therefore,
. Therefore,  is a solution of (i).
is a solution of (i).
Remark 2.2.
The assumption that  in Lemma 2.1 is essential. To see this, let us set
in Lemma 2.1 is essential. To see this, let us set

Then,  and
and  Thus,
Thus,  has a solution
has a solution  , while
, while  is inconsistent.
is inconsistent.
3. Least Squares Solution
For any matrix  of
of  and for any vector
and for any vector  , consider the linear equation
, consider the linear equation

Equation (3.1) may be consistent (if  ) or inconsistent (if not). In the second case we are seeking for such
) or inconsistent (if not). In the second case we are seeking for such  that the residual vector
that the residual vector  be as small as possible.
be as small as possible.
Definition 3.1.
Any vector  is said to be the Least Squares Solution (LSS) of (3.1) if
is said to be the Least Squares Solution (LSS) of (3.1) if

The following theorem shows that this definition is not empty and reduces the LSS of an inconsistent equation (3.1) to the ordinary solution of a consistent one.
Theorem 3.2.
-
(a)
Equation (3.1) has at least one LSS.
-
(b)
Vector
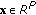 is an LSS of (3.1) if and only if
is an LSS of (3.1) if and only if 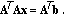 (3.3)
(3.3)
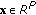 is an LSS of (3.1) if and only if
is an LSS of (3.1) if and only if 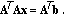
-
(c)
Condition (3.3) is equivalent to
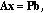 (3.4)
(3.4)
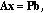
where  is the orthogonal projector onto
is the orthogonal projector onto  defined by (2.4).
defined by (2.4).
-
(d)
General solution of (3.3) may be presented in the form
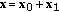 , where
, where 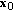 is a particular solution, while
is a particular solution, while 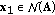 .
.
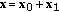 , where
, where 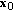 is a particular solution, while
is a particular solution, while 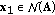 .
.Remark 3.3.
In the statistical literature, (3.3) is said to be normal.
Proof.
By properties of the projector  , we get
, we get

with the equality if and only if (3.4) holds. Moreover, by definition of  , (3.4) is consistent and, by Lemma 2.1, it is equivalent to (3.3).
, (3.4) is consistent and, by Lemma 2.1, it is equivalent to (3.3).
Statement (d) follows directly from definition of kernel.
4. Gauss-Markov Model and Gauss-Markov Theorem
Let  be an arbitrary random vector in
be an arbitrary random vector in  with finite second moment
with finite second moment  . Then there exist a unique vector
. Then there exist a unique vector  and a unique symmetric nonnegative definite matrix
and a unique symmetric nonnegative definite matrix  of
of  such that
such that

for all vectors  and all matrices
and all matrices  and
and  of
of  rows. Traditionally, such
rows. Traditionally, such  and
and  are called the expectation and the dispersion of the random vector
are called the expectation and the dispersion of the random vector  .
.
As usual, we will assume that  and
and  have the representations
have the representations

where  is a given matrix of
is a given matrix of  while
while  and
and  are unknown parameters. We will refer to the structure
are unknown parameters. We will refer to the structure  as to the standard Gauss-Markov model. In the context of the model we will consider unbiased estimation of the parametric vector
as to the standard Gauss-Markov model. In the context of the model we will consider unbiased estimation of the parametric vector  , where
, where  is of
is of  , by estimators of the form
, by estimators of the form  , where
, where  is of
is of  matrix. Since
matrix. Since  is unbiased if and only if
is unbiased if and only if  for all
for all  ,
,  is estimable if and only if
is estimable if and only if

Without loss of generality, we may and will assume that  . We note that such a matrix
. We note that such a matrix  is uniquely determined by
is uniquely determined by  .
.
The well-known Gauss-Markov theorem provides a constructive way for estimation of the function  . It is based on a solution of the normal equation
. It is based on a solution of the normal equation  which plays the role of the estimator for
which plays the role of the estimator for 
Theorem 4.1.
For any estimable  in the standard Gauss-Markov model
in the standard Gauss-Markov model  , there exists a unique linear unbiased estimator with minimal dispersion. This estimator, called the Least Squares Estimator (LSE) of
, there exists a unique linear unbiased estimator with minimal dispersion. This estimator, called the Least Squares Estimator (LSE) of  , may be presented in the form
, may be presented in the form  , where
, where  is an arbitrary LSS of
is an arbitrary LSS of  or, equivalently, it is a solution of the normal equation
or, equivalently, it is a solution of the normal equation

Proof.
By Theorem 3.2 the condition  is equivalent to
is equivalent to  . Therefore, by (4.3), for any estimable
. Therefore, by (4.3), for any estimable  and for any solution
and for any solution  of (4.4), the statistic
of (4.4), the statistic  is unbiased. On the other hand,
is unbiased. On the other hand,

Hence, any unbiased estimator of  may be presented in the form
may be presented in the form  , where the first component is the LSE of
, where the first component is the LSE of  while
while  . In particular the components are not correlated. Therefore, the variance of the sum is greater than the variance of the LSE
. In particular the components are not correlated. Therefore, the variance of the sum is greater than the variance of the LSE  , unless
, unless  . Moreover, by Theorem 3.2(d) this estimator is invariant with respect to the choice of the LSS
. Moreover, by Theorem 3.2(d) this estimator is invariant with respect to the choice of the LSS  . In consequence, the LSE of the function
. In consequence, the LSE of the function  is unique.
is unique.
References
Kruskal W: The coordinate-free approach to Gauss-Markov estimation, and its application to missing and extra observations. In Proceedings of 4th Berkeley Symposium on Mathematical Statistics and Probability. Volume 1. University of California Press, Berkeley, Calif, USA; 1961:435–451.
Kruskal W: When are Gauss-Markov and least squares estimators identical? A coordinate-free approach. Annals of Mathematical Statistics 1968, 39: 70–75. 10.1214/aoms/1177698505
Scheffé H: The Analysis of Variance. John Wiley & Sons, New York, NY, USA; 1959:xvi+477.
Rao CR: Linear Statistical Inference and Its Applications. 2nd edition. John Wiley & Sons, New York, NY, USA; 1973:xx+625.
Rao CR, Mitra SK: Generalized Inverse of Matrices and Its Applications. John Wiley & Sons, New York, NY, USA; 1971:xiv+240.
Bapat RB: Linear Algebra and Linear Models, Universitext. 2nd edition. Springer, New York, NY, USA; 2000:x+138.
Seber GAF: Linear Regression Analysis. John Wiley & Sons, New York, NY, USA; 1977:xvii+465.
Stępniak C: Through a generalized inverse. Demonstratio Mathematica 2008, 41(2):291–296.
Acknowledgment
Thanks are due to a reviewer for his comments leading to the improvement in the presentation of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Stępniak, C. From Equivalent Linear Equations to Gauss-Markov Theorem. J Inequal Appl 2010, 259672 (2010). https://doi.org/10.1155/2010/259672
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/259672